なんで突然,文字コードのお勉強に取り組んでいるかというと,久しぶりに,Joyful Note を見に行ったら,Ver.4.5 になっていて,カスタマイズしようと思ったら,正規表現で引っかかっちゃったのだ。何で,Joyful Note のカスタマイズに取り組もうとしているかというと,去年かかわったこれのせい。
引っかかったのは, joyful.cgi の中の,
# キーワード検索準備(Shift_JIS定義)
my $ascii = ‘[x00-x7F]’;
my $hanka = ‘[xA1-xDF]’;
my $kanji = ‘[x81-x9FxE0-xFC][x40-x7Ex80-xFC]’;
というところ。これは,もとの掲示板が Shift_JIS エンコードだから,(Shift_JIS定義)をやっているのだろう。ということは, EUC-JP にするなら,当然,(EUC-JP定義)を, UTF-8 にするなら,(UTF-8定義)をしなければいけないのではないかと思ったわけだ。前のバージョン(この間カスタマイズしたのは,3.71)には,この部分はなかった。実際には,同じ作業をやっている部分があったのかもしれないが,こういう形では見えなかったので,気づかなかった。
で,まずは改めて文字コードのお勉強から。参考にさせていただいたサイトはここ。参考にさせていただいたところは,間違いないようだが,文字コードについては,間違ったことを書いているところもあったから,要注意。まぁ,ネットていうのは,いつもそうだけどね。不安なときの確認は,やはり,本家。JISについては, 日本工業標準調査会 , UNICODE については, The Unicode Consortium を参照すること。
それから, Unicode そのものや Unicode と UTF-8 や UTF-16 との関係についての話は,ここの説明が一番よくわかった。大変に読みやすい。ありがたかった。
では,順番に調べて行ってみる。
- $ascii = ‘[x00-x7F]’ について。
これは,EUC-JP,UTF-8でも同じだから,このままでいいだろう。- 注:厳密にいうと,UTF-8の場合,円マーク ¥ (Shift_JIS,EUC-JPと同じ16進コードの場合は \ になる) とオーバーライン ‾ (Shift_JIS,EUC-JPと同じ16進コードの場合は ~ になる) は,( )内に書いたように異なっている。オーバーラインのほうはあまり意識に上ってこないかもしれないが, ¥ を打ったつもりなのに,表示が \ になってしまったという経験は,よくあると思う。日本語用フォントにおいて,この部分は,いまだに特例扱いのようだ。何しろ,円マークは日本の一般社会の頻出記号だから,さかのぼって直すとなると大変なんだろうと,推察した。本当の理由は知らない。
- $hanka = ‘[xA1-xDF]’ について。
これは, JIS0201.TXT の第1列をを見ると,半角カナの話であることが分かる。半角カナは,EUC-JPでは, 8EA1~8EDF だから,$hanka = ‘x8E[xA1-xDF]’でいいのか。それとも,EUC-JP の場合,1バイト目に 8E が出て来るのは,半角カナだけだから, x8E 部分のチェックだけでいいのだろうか。この辺は,実装の問題なのか?JIS0201.TXT 見ると,UNICODEの場合,半角カナに対応するのは,FF61~FF9Fとなっている。これを The Unicode Consortium の文書 Conformance の Table 3-6. UTF-8 Bit Distribution と Table 3-7. Well-Formed UTF-8 Byte Sequences に則って変換してみる。
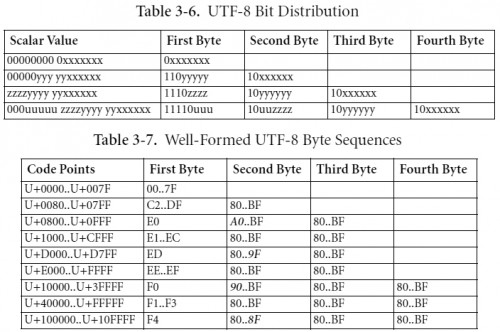
まずは,FF61 (16進) —> 11111111 01100001 (2進) とする。
Table 3-6.に照らし合わせると,対応は以下のようになる。z z z z y y y y y y x x x x x x 1 1 1 1 1 1 1 1 0 1 1 0 0 0 0 1 さらに,Table 3-6.のルールを適用すると,結局,1バイト目から3バイト目は,以下の3つの2進数になる。
1バイト目 2バイト目 3バイト目 ルール 1 1 1 0 z z z z 1 0 y y y y y y 1 0 x x x x x x 対応する2進数 1 1 1 0 1 1 1 1 1 0 1 1 1 1 0 1 1 0 1 0 0 0 0 1 したがって,11101111 10111101 10100001 (2進) —> EFBDA1 (16進) となることがわかる。同様に,FF9F (16進) —> EFBE9F (16進) になる。
細かく調べてみると, UTF-8 で Shift_JIS の A1~DF に対応する部分は, EFBDA1~EFBDBF までと, EFBE80~EFBE9F に分かれていることがわかる。ということになると, UTF-8 の場合は,
$hanka = ‘xEFxBD[xA1-xBF]|xEFxBE[x80-x9F]’
ということになりそうだ。 - $kanji = ‘[x81-x9FxE0-xFC][x40-x7Ex80-xFC]’ について。
これは, JIS0208.TXT の第1列だと,実体のあるところだけをズラッと並べてあるから見づらいんだが,範囲は Shift_JIS だと,上位1バイト 0x81~0x9f , 0xe0~0xef ,下位1バイト 0x40~0x7e , 0x80~0xfc に収まっている。 JISX0208 の範囲だから,JIS第1第2水準漢字だということだ。
まあ,この範囲だと, EUC-JP は,上位1バイトも下位1バイトも 0xa1~0xfe に収まっているから,多分,$kanji = ‘[xA1-xFE][xA1-xFE]’ でいいんだろう。問題は UTF-8 で, Shift_JIS と EUC-JP はコードにしたときの並び順が同じだからいいが, UTF-8 は UNICODE 由来だから順序が違う。といって, Shift_JIS と EUC-JP の順序を無視して, UNICODE だけで行くと,日本語では一般的でない漢字も遠慮なく入ってくる。その辺が,日本国内を視点に考えられた Shift_JIS ・ EUC-JP と, UNICODE の違いだ。
こういう場合は,1度 UTF-8 になっているものを EUC-JP とかに戻して考えるのが一般的なのだろうか。どういう方法が,一般的なのかは,別にして, JISX0208 の範囲の UNICODE から, UTF-8 を考えて変換表を作ってみた。上記の参考ページにあるようなものを自前で作ってみたわけだ。これをやるには,いろんな方法があるのだろうが,使い慣れているEXCELでやってみた。で,出来上がったのが,これ。並び順は,作成した UTF-8 順。UTF-8 と UNICODE の部分の色分けは,Table 3-7.の Well-Formed の確認のためにつけたもの。 Shift_JIS と字の部分の色分けは,青が第一水準,黄が第二水準(厳密にいうと,第一,第二は漢字に対して使うものらしいが……)。
漢字の部分で,青と黄が入り混じっている。おまけに, UTF-8 は連続数になっていない。 UNICODE の漢字は基本的に画数で並んでいるから,常用漢字が基本に来る JIS と対比すると,こうなるのはまあ当然。うーん,やはり,EUC-JP に戻してフィルタかけるのが現実的なのかなぁ。
と,ここまでやってきて,ようやく,Joyful Note のカスタマイズに入れそうな気がしてきたが,まだ簡単には,行きそうにない(爆)。